Overview
The Smedge Python API can be used for communicating with Smege. It is a simple wrapper around the command line interface, which makes it great for one-shot type actions (submitting jobs, changing settings, making a query). For long running processes, the overhead of establishing a connection for every communication can impact performance, and you should use the C++ API directly.
Contents
Configuration
Setting up Python
Connecting to Smedge
Responding to events with Python
Query Grammar
Examples
Submitting and Updating Jobs
Querying Jobs
Controlling Engines
Encode Rendered Frames into Movies
Reference
Properties
SMEDGEClasses
HistoryElementParameterPathTranslationPoolProductSmedgeComponentError
Types
AnyPoolTypeEngineTypeJobHistoryTypeJobTypeNameOrIDNameOrIDListParameterListRegexListTranslationTypeTranslationListTypeConfiguration
Setting up Python
In order to find the Smedge Python package, you will need to make it available to your Python runtime environment. The Python API lives in the Smedge distribution with the other components. You can find the exact folder where Smedge is running from for you by using the SmedgeGui menu command System > Smedge Files > Browse the Application Folder.
| Windows | set PYTHONPATH=C:\Program Files\Smedge\python |
| Mac | export PYTHONPATH=/Applications/Smedge.app/Contents/MacOS/python |
| Linux | export PYTHONPATH=/opt/smedge/python |
If all goes well, you should be able to import smedge in your Python interpreter.
Connecting to Smedge
Python Smedge will communicate just like any other Smedge component on the machine. Generally speaking, if you can use the SmedgeGui on a machine, Python should work. You may need to update any firewall settings to allow the Smedge command line components (Submit, Job, Engine, PoolManager, and ConfigureMaster) to communicate. See the Smedge documentation for more information about connectivity.
There are a few environment variables that can modify how the Python API uses the CLI:
| Variable | Meaning |
|---|---|
SMEDGE | Override the Smedge program folder location (default assumes the code is in the default deployment location). |
SMEDGE_MASTER | Override the Master location. You can specify the master hostname or IP and optionally the port. |
SMEDGE_MASTER_PORT | Override the Master port (default is 6870). |
SMEDGE_LOG_LEVEL | Set the log file level (default is 5, debug level is 6). |
SMEDGE_CONNECT_TIMEOUT | Set number of seconds the CLI tool will wait trying to connect before returning a failure (default is 10) |
Responding to events with Python
Smedge has a ton of places where you can hook into events using a command line interface and a variable substitution system. You can find full details of these events in the Smedge documentation.
Using Python for these events is as simple as spawning a Python script from a command line. For the event command, put your python command line executable, followed by the script path you want to use, followed by any arguments you need to send to your job. To get information about the object that the event is related to (e.g., the job that just started, or the engine that just finished a work unit), use the $(name) variable substation system.
For example, to run the job_finished.py script with the parameters of the job ID and the value of the job’s note, your event command would look something like this:
python job_finished.py $(ID) $(Note.Enquote)
This system works with job event commands, engine event commands, and in the Herald. See the Smedge documentation for full details, as each event command system has different variables available depending on the context.
Query Grammar
When searching for jobs, you can use a query to limit what jobs you get. The grammar for the query system is described here. Note that Smedge will generally do comparisons in a case insensitive manner, so the names ID, Id, and id would all be treated the same.
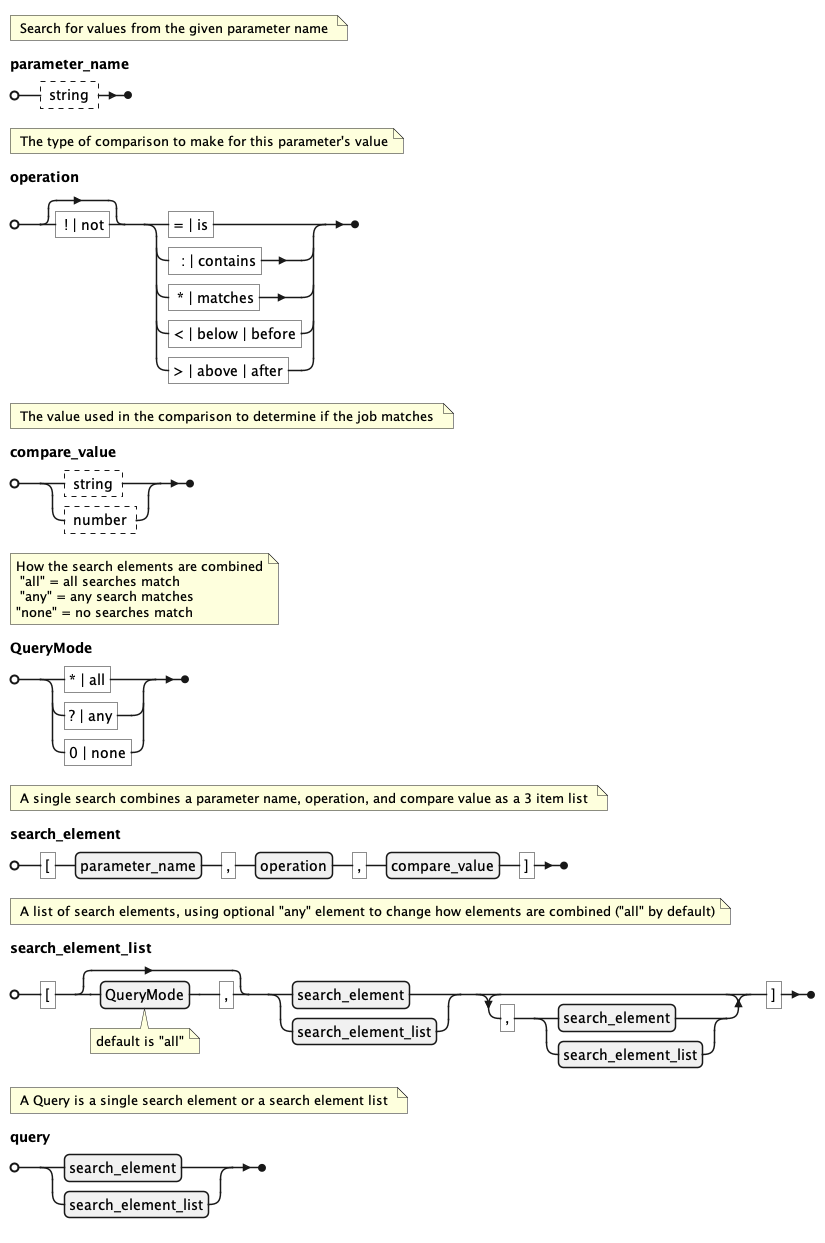
In Python, the grammar is represented using lists and strings. See the examples below.
Examples
Submitting and Updating Jobs
Submit a simple Maya job:
>>> job = {
... "Name": "My Job",
... "Type": "Maya",
... "Scene": "/path/to/the/scene.mb",
... "Range": "1001-1250",
... }
>>> result = submit_jobs(job)
>>> print(result)
[UUID('8ad51e37-127e-4894-aefb-8e8273c111cf')]
Submit two Maya jobs for separate render layers, and a Nuke job that waits for frames to finish from both jobs before comping them. Note that the comp job’s priority is higher than the render jobs, so that the per-frame waiting works:
>>> maya_job = {
... "Type": "Maya",
... "Scene": "/path/to/the/scene.mb",
... "Range": "1001-1250",
... "Priority": 50,
... }
>>> render_jobs = []
>>> layers = ["layer1", "layer2"]
>>> for layer in layers:
... layer_job = maya_job.copy()
... layer_job["Name"] = f"Render - {layer}"
... layer_job["ID"] = uuid4()
... layer_job["Extra"] = f"-rl {layer}"
... render_jobs.append(layer_job)
>>> nuke_job = {
... "Name": "Comp layers",
... "Type": "Nuke",
... "Scene": "/path/to/the/comp_script.nk",
... "Range": "1001-1250",
... "Priority": 55,
... "WaitForJobID": [job["ID"] for job in render_jobs],
... "WaitForWholeJob": 0,
... }
>>> render_jobs.append(nuke_job)
>>> result = submit_jobs(render_jobs)
>>> print(result)
[UUID('178b043e-4a28-4235-acbc-642c7480c360'),
UUID('12f1146d-a16e-4a02-ba69-577b22a94757'),
UUID('b5f40f8b-795a-43ef-bf12-aca6b6d7289f')]
Get the pools, and create a new job using a named pool, if available (otherwise it will use the default whole-system pool):
>>> job = {
... "Name": "Test Job",
... "Type": "Maya",
... "Scene": "/path/to/the/scene.mb",
... "Range": "1001-1050",
... }
>>> all_pools = get_pools()
>>> for pool in all_pools:
... if job["Type"] in pool.name:
... job["Pool"] = pool
... break
>>> result = submit_jobs(job)
>>> print(result)
[UUID('a29f0cb2-11e1-42a9-9b72-6c5f5be5f671')]
Change a job’s priority:
>>> job = update_jobs("a29f0cb2-11e1-42a9-9b72-6c5f5be5f671", "Priority", 100)
Pause several jobs at once:
>>> jobs = [UUID('178b043e-4a28-4235-acbc-642c7480c360'),
... UUID('12f1146d-a16e-4a02-ba69-577b22a94757'),
... UUID('b5f40f8b-795a-43ef-bf12-aca6b6d7289f')]
>>> update_jobs(jobs, "Status", -1)
Query for Jobs
Get all jobs in the system:
>>> jobs = get_jobs()
Get one specific job directly:
>>> jobs = get_jobs("a29f0cb2-11e1-42a9-9b72-6c5f5be5f671") >>> assert len(jobs) < 2 # empty list if not found, else just this one job
Get several known jobs:
>>> job1_id = UUID("a29f0cb2-11e1-42a9-9b72-6c5f5be5f671")
>>> job2_id = UUID("178b043e-4a28-4235-acbc-642c7480c360")
>>> jobs = get_jobs(ids_to_query([job1_id, job2_id]))
>>> assert len(jobs) < 3 # 0, 1, or both jobs will be found
Get all jobs for a given user:
>>> jobs = get_jobs(query=["Creator", "contains", "Joe"])
Get all jobs created more than 3 days ago:
>>> creation_time = datetime.now() - timedelta(days=3) >>> jobs = get_jobs(["Created", "before", datetime_to_rtime(creation_time)])
A more complicated query, that matches any one of the following:
- The job type is neither
MayanorNuke - The name starts with a pattern like
Cleanup 12345 - The scene's parent folder name does not contain the word
Final, the priority is less than50, and either:- The note is empty, or
- The last error is not empty
This is fairly contrived, but shows the power of the query grammar. You can use the full parameter name and command substitution system as part of your query. It is a matter of balance in your workflow to determine how broad to make your query in order to get the performance your pipeline needs.
>>> jobs = get_jobs(query=[ ... "any", ... [["Type", "!=", "Maya"], ["Type", "!=", "Nuke"]], ... ["Name", "*", r"^Cleanup \d{5}"], ... [ ... ["Scene.Path.File", "!:", "Final"], ... ["Priority", "<", 50], ... ["?", ["Note", "=", ""], ["LastError", "!=", ""]], ... ], ... ])
Controlling Engines
Enable all engines that have a name that matches RENDER_####:
>>> enable_engines(regex=r"RENDER_\d{4}")
Set the Use GPUs setting to 4 on all engines in the system:
>>> set_engines({"UseGPUs": 4}, regex=".*")
Set up event handlers for the work finished events on all engines:
>>> events = {
... "WorkFinishedSuccessfulEvt": "python /sw/pipeline/work_finished.py 'success' $(ID) $(Parent) $(Type) $(Scene.File.Enquote)",
... "WorkFinishedUnsuccessfulEvt": "python /sw/pipeline/work_finished.py 'failed' $(ID) $(Parent) $(Type) $(Note.Enquote)",
... }
>>> set_engines(events, regex=".*")
Encode Rendered Frames into Movies
Here is a script that takes a job ID as a single input and creates an ffmpeg transcode job for every output image format in the job. Note that there is no error checking or validation in this script, so it would not be suitable for production:
import pathlib import sys import smedge # Get the job ID from the first argument to the script job_id = sys.argv[1] # Find that job (assumes the job exists) job = smedge.get_jobs(job_id)[0] ffmpeg_jobs = [] # Loop through the ImageFormats parameter: the known or detected output image paths for format in job["ImageFormat"]: # Each format will be a path with a printf format specifier for the frame number # like: '/path/to/the/images/filename.%04d.exr' format = pathlib.Path(format) name = pathlib.Path(format.stem).stem # 'filename' ext = format.suffix[1:] # 'exr' ffmpeg_jobs.append({ "Name": f"Encode: {name} - {ext} to x264", "Type": "ffmpeg", "InfileOptions": "-r 24", # flags that go before the -i "Scene": format, # The input image specifier (-i flag) "OutfileOptions": "-v:c libx264 -pix_fmt yuv420p", # flags that go before the output "OutputFile": format.parent / f"{name}_x264.mp4", # the output filename "CPUs": 0, "Range": 1, "WaitForJobID": job_id, }) # Submit all the encode jobs at once smedge.submit_jobs(ffmpeg_jobs)
If this script was saved as /sw/pipeline/encode.py, you could add it to your Maya job at submit time:
job = {
"Name": "My Job",
"Type": "Maya",
"Scene": "/path/to/the/scene.mb",
"Range": "1001-1250",
"JobFinishedEvt": "python /św/pipeline/encode.py $(ID)",
}
result = submit_jobs(job)
You could also use the Herald to run the command in response to the event on any arbitrary machine instead of the Master. This may be useful if you had specific hardware that was required to be triggered on specific job events, like a hardware encoder or broadcast device. Herald can respond to any event in the job lifecycle for any job in the system, including job creation. It can also pre-filter events as part of the configuration. See the User Manual for more information.
Reference
Most Smedge data is passed around as dicts with string names. Smedge uses UUIDs for its IDs, so any place where Smedge uses an ID you can pass either a str or a UUID value.
Properties
Classes
Smedge defines a few utility classes to help with certain concepts. These are generated by the API when getting data as needed, and are handled for sending data as indicated below.
@dataclass(frozen=True) class HistoryElement
A class that combines all of the elements from a single history element from a job's history.
| member | type | description |
|---|---|---|
name | str | The work name |
work_id | UUID | The ID of the work run |
time | datetime | The timestamp of this history event |
status | int | The work run status code at the time of this event |
engine_id | UUID | The ID of the engine that was running this work |
note | str | Any note connected to this history event |
def __init__(name, work_id, time, status, engine_id, note)
@dataclass(frozen=True) class Parameter
A class that contains the data that define a parameter, used in Product definition.
| member | type | description |
|---|---|---|
type | str | The type of parameter this is |
flags | typing.List[str] | A list of flags that apply to this parameter |
settings | typing.Dict[str, str] | The other string settings that apply to this parameter |
choices | typing.Dict[str, str] | An optional map of choices with internal name as key and display name as value |
parameters | ParametersList | An optional list of sub-parameters if this parameter is Parameters type |
name | str | A shortcut for getting the name setting for this parameter |
default | str | A shortcut for getting the default setting for this parameter |
def __init__(type, flags, settings, choices, parameters)
Create a new Parameter object with the given values.
@classmethod def from_dict(cls, in_dict)
Class factory method to create a new Parameter object from a JSON dict
PathTranslation = namedtuple("PathTranslation", ["windows", "linux", "mac"])
A namedtuple class that contains the set of roots for each platform that represent one possible translation.
| index | member | type | description |
|---|---|---|---|
0 | windows | str | The path root on Windows platforms |
1 | linux | str | The path root on Linux platforms |
2 | mac | str | The path root on Mac platforms |
def __init__(windows, linux, mac)
class Pool(object)
Full information about a pool, both its ID and name. It will compare equality with a str, a UUID or another Pool object, preferring comparison by ID over name, if possible. These are returned by the pool methods. You can use a Pool as the "Pool" value when you submit a job, but you don't have to. Converting to str will return the string form of the ID. Converting to repr will show both the ID and the name.
| member | type | description |
|---|---|---|
id | UUID | The pool ID |
name | str | The pool name |
def __init__(pool_id, pool_name)
@dataclass(frozen=True) class Product
A class that contains the data that define a "product" in Smedge. This provides the metadata to parse and validate the job settings, engine settings, and master settings for a type of worker.
| member | type | description |
|---|---|---|
type | UUID | The product ID |
smedge_class | str | The name of the class of job from Smedge, which affects how it operates |
name | str | The name of the product |
queue | int | The dispatch queue to use (0 is the "general purpose" queue, 1 is the "file transfer" queue, 2 is the "maintenance" queue). |
aliases | typing.List[str] | An optional list of alternate names to find this product |
parameters | ParametersList | A list of all the Parameter objects for the product, in order of display as configured in the product settings. |
required_parameters | ParametersList | A list of the required Parameter objects for the product, alphabetical by parameter name. |
def __init__(type, smedge_class, name, queue, aliases, parameters)
Create a new Product object with the given values.
@classmethod def from_dict(cls, in_dict)
Class factory method to create a new Product object from a JSON dict
Types
These are the custom types defined and used by the API. Note that these are not classes meant for instantiation as run-time objects.
AnyPoolType = typing.Union[str, UUID, Pool]
JobHistoryType = typing.List[HistoryElement]
TranslationType = typing.Union[PathTranslation, list, tuple]
A type that represents a single set of path translation roots.
TranslationListType = typing.Union[TranslationType, typing.List[TranslationType]]
A type that represents a single path translation root group or a list of them.
Methods
def add_path_translations(translations: TranslationListType)
Add path translations.
| argument | type | description |
|---|---|---|
translations | TranslationListType | a group of path translation roots or a list of such sets. Each translation group must include a root for all three supported platforms, but that root can be an empty string. |
def conform_job(job: JobType) -> JobType
Ensures that a job's values fit with the requested product. This will get the product info from the Master, then use it to validate the input job object's values. Any lists or dicts will be turned into a string based on product settings if possible. This is the inverse process of pythonize_job. This is called automatically when you use submit_jobs.
| argument | type | description |
|---|---|---|
job | JobType | A job built in Python |
Returns a modified job dict ready to submit. Raises ValueError if you did not supply a valid job dict, the job has no type, the type given was not found in the system, or not all required parameters were found in the job dict.
def datetime_to_rtime(from_datetime: typing.Optional[datetime]) -> str
Convert a datetime object to an RLib time number value. This will be a large integer (returned as a string), not a formatted date and time. This is the inverse operation of extract_datetime.
| argument | type | description |
|---|---|---|
from_datetime | None, datetime | A datetime object. |
def delete_jobs(jobs: NameOrIDList, stop_work: bool = False)
Delete jobs. This does not wait for the jobs to be deleted, and will return immediately after successfully sending the request to the Master.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
stop_work | bool | True will immediately abort any running work. False (the default) allows work to finish normally, but no new work will be sent. |
def delete_pools(pools: typing.Union[AnyPoolType, typing.List[AnyPoolType]])
Delete pools.
| argument | type | description |
|---|---|---|
pools | str, UUID, Pool, list | A pool, pool name, pool ID or a list of them. |
def disable_engines(
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
stop_work: bool = False,
)
Disable engines to run any work. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
stop_work | bool | True will immediately abort any running work. False (the default) allows work to finish normally. |
def disable_product(
product: NameOrID,
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
)
Disable engines to run work from the given product. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
product | str, UUID | The name, ID, or shortcut for a product. |
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
def download_file(engine: NameOrID, file: NameOrID) -> str
Download a file from an engine. The file must exist on the engine and must be actively shared to the network.
| argument | type | description |
|---|---|---|
engine | str, UUID | The name or ID of the engine to get the file from. |
file | str, UUID | The path or shared ID of the file to get. |
def enable_engines(
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
)
Enable engines to run any work. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
def enable_product(
product: NameOrID,
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
)
Enable engines to run work from the given product. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
product | str, UUID | The name, ID, or shortcut for a product. |
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
def extract_datetime(from_string: str) -> typing.Optional[datetime]
Convert a Smedge date/time string or number value to a datetime object. This can take as input either the large number format used by Smedge internally or a formatted string in the default Smedge date/time format (YYYY-mm-dd HH:MM:SS.ms). This is the inverse operation of datetime_to_rtime.
| argument | type | description |
|---|---|---|
from_string | str | The input string to convert. Can be either a big number (RLib time format) or a standard Smedge formatted time string. |
Returns a datetime object if the conversion was successful, otherwise None.
def find_parameter(
parameters: ParameterList, name: str
) -> typing.Optional[Parameter]
Finds the given parameter by name regardless of case
| argument | type | description |
|---|---|---|
parameters | ParameterList | The list of parameters to search. |
name | str | The name to search for |
Returns a Parameter object if the parameter was found, otherwise None.
def find_value(from_dict: Mapping, name: str, default: any = None) -> any
Finds a value in a dict case insensitive or returns default.
| argument | type | description |
|---|---|---|
from_dict | Mapping | A dict or dict-like object to search |
name | str | The key to search for |
default | any | The default value to return if the key is not found |
def get_engine_dispatch_log(
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
) -> typing.Dict[UUID, str]
Get engine dispatch log reports. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
Returns a dict with the key being the UUID of the engine, and the value being a string with the report from the Master about the dispatch result for this engine.
def get_engines(
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
) -> typing.List[EngineType]
Get engine settings. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
Returns a list of engine objects, each of which is a dict of Engine settings and product options. Product options have a key that will be the string form of the product UUID, and the value will be a child dict with the overrides for that product. For all other settings the value will be a str.
def get_job_dispatch_log(jobs: NameOrIDList) -> typing.Dict[UUID, str]
Get job dispatch log reports.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
Returns a dict with the key being the UUID of the job, and the value being a string with the report from the Master about the dispatch result for this job.
def get_job_history(jobs: NameOrIDList) -> typing.Dict[UUID, JobHistoryType]
Get the raw job history.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
Returns a dict with the key being the UUID of the job, and the value being a list of HistoryElement objects.
def get_jobs(
query: typing.Optional[typing.Union[str, UUID, list]] = None,
get_all_parameters: bool = True,
) -> typing.List[JobType]
Get jobs. Gets all jobs if None is requested.
| argument | type | description |
|---|---|---|
query | None, str, UUID, list | A Job ID or a query to filter what jobs to get. See Query Grammar and Examples |
get_all_parameters | bool | True fills out each object with default values using the product info, and makes the jobs more Pythonic (lists are actual list objects, numbers, dates, and UUID values are the correct type, etc.). False returns only the non-default values in their raw str format. See pythonize_job. |
Returns a list of objects, each being a dict of the job settings. To build a query for a list of jobs, use ids_to_query.
def get_path_translations() -> typing.List[PathTranslation]
Get the current list of path translations.
Returns a list of PathTranslation objects. List may be empty. All translation groups will have three values, but the values may be empty.
def get_product_info(
product: typing.Optional[str] = None,
) -> typing.Optional[typing.Union[Product, typing.List[Product]]]
Get product information. Gets all products if None is requested.
| argument | type | description |
|---|---|---|
jobs | None, str | A product name, shortcut, or ID |
If you requested a specific product, the return value will be a dict of the product settings, if found, or None. If you requested all products, the return value will be a list of product dicts.
def ids_to_query(job_ids: NameOrIDList) -> list
Converts a job ID or list of IDs, into a Smedge query.
| argument | type | description |
|---|---|---|
job_ids | str, UUID, list | A job ID or a list of job IDs. |
Returns a Smedge query list suitable for use in get_jobs. Raises ValueError if the list is empty, and TypeError if any of the elements could not be converted to a valid job UUID.
def pause_jobs(jobs: NameOrIDList, stop_work: bool = False)
Pause jobs.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
stop_work | bool | True any running work from the jobs will be stopped. False (the default) will allow any running work to finish normally. |
def preempt(jobs: NameOrIDList)
Stop all work on the farm from the listed jobs without pausing the jobs.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
def pythonize_job(job: JobType) -> JobType
Expands values to be more Pythonic. Uses the product info to turn IDs into UUID objects, expand lists and sub-parameters, and adds all default values from the product. This is the inverse process from conform_job. This is generally called automatically by get_jobs.
| argument | type | description |
|---|---|---|
job | JobType | A job dict |
def remove_path_translations(roots: typing.Union[str, typing.List[str]])
Remove path translations
| argument | type | description |
|---|---|---|
roots | str, list | One or more roots to search for and remove. If the given values match any of the roots in a translation group, that translation group will be removed. |
def rename_pool(pool: AnyPoolType, new_name: str) -> Pool
Rename a pool.
| argument | type | description |
|---|---|---|
pool | str, UUID, Pool | The ID and/or current name of the pool to rename |
new_name | str | The new name to give the pool. |
Pool object with the updated pool info.
def reset_engine_failures(
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
)
Reset engine failure counts. If you supply no engine names, IDs, or regex strings, it will affect the local machine's Engine if available.
| argument | type | description |
|---|---|---|
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
def reset_job_failures(jobs: NameOrIDList)
Reset the failure counts for the given jobs.
| argument | type | description |
|---|---|---|
jobs | None, str, UUID, list | A job ID or a list of job IDs. |
def resume_jobs(jobs: NameOrIDList)
Resume paused jobs.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
def set_engines(
settings: EngineType,
engines: typing.Optional[NameOrIDList] = None,
regex: typing.Optional[RegexList] = None,
)
Set engine data using a template dict. Use a setting name and str value, or use the UUID of a product and the value will be a child dict of setting name and str values that apply to the product with that UUID.
| argument | type | description |
|---|---|---|
settings | dict | The settings to apply to the engines. |
engines | None, str, UUID, list | A name, an ID, or a list of names or IDs. |
name | None, str, list | A regex pattern or list of regex patterns to engine names. |
def submit_jobs(
jobs: typing.Union[JobType, typing.List[JobType]],
paused: bool = False,
) -> typing.List[UUID]
Submit one or more jobs to Smedge.
A Job is a dictionary of values for the job settings. The values to supply depend on the type of Job being submitted. See the Smedge Administrator Manual for all possible values for all default job types along with current defaults and required values. If you do not supply "id" as one of the Job dict values, the jobs will get new unique IDs. Most values can be left out to use the defaults.
If you need to submit a bunch of jobs at the same time, it's far more efficient to submit them all at once with a list of jobs than one at a time. If you need to create dependencies between jobs, generate an ID for the lead job and use that in the dependent job's WaitForJobID value.
This will generate a temp file with the job data. If anything goes wrong during the submit process, this file will be left in the temp folder to allow you to see if job data is causing the problem. If all goes well, it will be automatically removed.
If you just want to change a single parameter on one or more jobs, it is faster to use update_jobs.
| argument | type | description |
|---|---|---|
jobs | dict, list | A job dict or a list of job dicts. |
paused | bool | If True, jobs will be submitted paused regardless of the status in the settings being sent. If False (the default), the job status in the settings will be used, if any, or jobs will be submitted unpaused and ready to work. |
Returns a list of UUIDs with the ID of each job successfully submitted. The IDs will be in the order that the jobs appeared in the input, even if the IDs themselves were generated internally because they were not supplied in the job data.
Raises ValueError if you did not supply a valid job dict or list of dicts, the job ID is invalid, or more than one job has the same ID.
def update_jobs(jobs: NameOrIDList, parameter: str, value: any)
Update a single parameter's value for one or more jobs. This is faster than using submit_jobs for updating a single parameter.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
parameter | str | The name of the parameter to update. |
value | any | The value to set. |
def usurp(jobs: NameOrIDList, minimum_priority: typing.Optional[int] = None)
Usurp the farm for the given jobs. Stops running work from any jobs with lower priority than the given jobs or the optional supplied value.
| argument | type | description |
|---|---|---|
jobs | str, UUID, list | A job ID or a list of job IDs. |
minimum_priority | None, int | A minimum priority to use instead of the job list |